
Initially, I wasn’t planning on even participating in the 2021 Google CTF event because it had a rating weight of 99.22 on CTFtime which speaks volumes about its immensive difficulty. I was rightfully positive about the fact that even the simplest challenges would be much more difficult than normal CTFs. I was still relatively new to CTFs (it had been nearly 5 months since I started) and I knew that this was definitely an ‘elite’ CTF which all the top teams would participate in.
The CTF time schedule was Sat, 17 July 2021, 08:00 SGT — Mon, 19 July 2021, 07:59 SGT. When it started at 8 am, I just briefly looked at the challenges incase there was something that I could even remotely think of attempting and turns out there wasn’t :( However, at 4 pm or after 12 hours, they released new challenges and one of them was the cryptography challenge known as “Pythia” which was a challenge about AES-GCM. I knew just a bit about how that worked and could understand what was happening in the attached server code so I thought that I could give it a shot. Instead of the usual team name ‘Isengard’, I instead chose ‘gcmTime’ for this CTF (because of the Pythia challenge). I called up Diamondroxxx and we immeditaly started working on Pythia and after solving that, we tried other challenges till the end of the CTF, working as a two man team.
As expected, even the easiest challenge (in terms of solves) would still be considered a medium difficulty challenge in some other CTFs (at least in my opinion). The challenges were of very high quality and most proved to be out of reach for us. In the end, we managed to solve 3 challenges and we ranked 80th out of 379 scoring teams.

Overall, this CTF was a fantastic learning experience and gave me a sense of what a top or elite CTF looked like, suffice to say it was very challenging…. Even for the challenges that I couldn’t solve but at least attempted, I managed to learn a lot and was introduced to new concepts which I had absolutely no knowledge about previously such as the Hidden Number Problem and Huffman Coding.
Below are the writeups :
| Challenge | Category | Points | Solves |
|---|---|---|---|
| Story | Crypto | 249 | 32 |
| Pythia | Crypto | 173 | 65 |
| Filestore | Misc | 50 | 321 |
Story
Server source code provided (this is in the Dart programming language) :
#!/usr/bin/env dart
import 'dart:convert';
import 'dart:io';
// NOTE: calculate and randomize functions are private (i.e., you don't have access).
import 'package:ctf_story/private.dart' show calculate, randomize;
int main(List<String> arguments) {
final flag = File('flag.txt').readAsStringSync();
print('Hello! Please tell me a fairy tale!');
var line = stdin.readLineSync(encoding: utf8);
if (utf8.encode(line).where((i) => i < 32 || i >= 128).isNotEmpty) {
print('There are unprintable characters in your story.');
return 0;
}
final firstText = line.toLowerCase();
var crcValues = calculate(utf8.encode(line));
print('The CRC values of your text are $crcValues.');
List<String> expectedValues;
do {
expectedValues = randomize(utf8.encode(line));
} while (expectedValues == crcValues);
if (expectedValues == null) {
print('Your story is too short. Bye!');
return 0;
}
print('But I am looking for a story of $expectedValues.');
line = stdin.readLineSync(encoding: utf8);
final secondText = line.toLowerCase();
crcValues = calculate(utf8.encode(line));
if (firstText != secondText) {
print('Perhaps you would like to start from scratch? Bye!');
return 0;
}
if (List.generate(
expectedValues.length, (i) => crcValues[i] == expectedValues[i])
.indexOf(false) <
0) {
print('What a lovely story! Your flag is ${flag}');
}
print('Bye!');
return 0;
}
When we connect to the server, we are prompted to enter some ASCII printable characters. The CRC values of the input is then calculated. CRC stands for a Cyclic Redundancy Check which is a kind of checksum / error detecting code. There are many variants of CRCs which encode messages with different lengths and polynomials. An exhaustive list of different CRC variants can be found here. After playing around with online CRC calculators, we realised that the three CRC values outputted by the calculate function corresponded to CRC-16 (also known as CRC-16 ARC), CRC-32C (also known as CRC-32/CASTAGNOLI or ISCSI) and CRC-64/XZ.
Great, so now we knew what the calculate function does. Moving on, each of the three CRC values is then converted to a different CRC value using an unknown randomize function. After that, these values are outputted and we are then prompted to input another set of ASCII characters. After that, the CRC values of our input is calculated and if it maches the values generated by the randomize function, we get the flag. The input had to also be at least 256 bytes as otherwise our session would end as our “story is too short”. Two things stumped us. Firstly, we were supposed to input two strings which had to match as shown by the line if (firstText != secondText) which would exit if our first input did not match the second. Secondly, we were confused as to how to figure out what randomize did exactly.
Turns out we were being incredibly foolish as it took us a long time to realize that our input is converted to lower case, final firstText = line.toLowerCase(); and so is our second input which means that our inputs could be the same but have different capitalizations (like aaaAAA and AAAaAA). The CRC values for our second input is calculated for that input and not the lower case string. This means that as long as we have different capitalizations for our input, we could bypass this check but the bigger question remained, now what exactly were we supposed to do?
Turns out Google (the organisers of this CTF) had written a CRC library in Dart where there was an option “To flip bits to obtain desired CRC values” which meant that by using this library, “one can call flipWithData or flipWithValue depending on whether they have access to the message, or only its calculated CRC value” which is exactly what we needed. We needed to flip the capitalizations (bits) of our original input (note that the difference between each ASCII value of a lower case and upper case character is always 32 and that the capitalization changes based on the binary value of the 6th bit so that is the bit that is flipped) based on the ‘random’ CRC values outputted by the server. Conveniently and coincidentally (maybe not?), the test CRC flipper that they provided already used the exact three variants used by the server in our challenge.
Based on that, we modified the code and made a Dart program which would calculate the desired string based on the random CRC values outputted by the server :
import 'dart:typed_data';
import 'package:test/test.dart';
import 'package:crclib/catalog.dart';
import 'package:crclib/crclib.dart';
import 'package:crclib/src/flipper.dart';
void expectSolution(int width, List<BigInt> checksums, BigInt target) {
var matrix = generateAugmentedMatrix(width, checksums, target);
var selected = solveAugmentedMatrix(matrix);
var calculated = 0;
for (var i = 0; i < checksums.length; ++i) {
if (selected[i]) {
calculated ^= checksums[i].toInt();
}
}
expect(calculated, target.toInt());
}
void expectNoSolution(int width, List<BigInt> checksums, BigInt target) {
var matrix = generateAugmentedMatrix(width, checksums, target);
var selected = solveAugmentedMatrix(matrix);
expect(selected, null);
}
void testFlipper(
ParametricCrc crc, String input, int low, int high, CrcValue target) {
var flipper = CrcFlipper(crc);
var data = Uint8List.fromList(input.codeUnits);
var positions = flipper.flipWithData(
data, List.generate(high - low + 1, (i) => i + low).toSet(), target);
expect(positions, isNotNull);
expect(positions, isNotEmpty);
expect(positions.length, lessThanOrEqualTo(crc.lengthInBits));
positions.forEach((p) {
var mask = 1 << (p % 8);
data[p ~/ 8] ^= mask;
});
expect(crc.convert(data), target);
}
void main() {
test('BitVector', () {
var oneInt = BitArray(32);
var twoInts = BitArray(64);
oneInt[0] = true;
expect(oneInt[0], true);
expect(oneInt[31], false);
twoInts[0] = true;
twoInts[32] = true;
expect(twoInts[0], true);
expect(twoInts[31], false);
expect(twoInts[32], true);
expect(twoInts[63], false);
expect(oneInt.length, 32);
expect(twoInts.length, 64);
expect(() => BitArray(-1), throwsArgumentError);
expect(() => oneInt[-1], throwsRangeError);
expect(() => oneInt[32], throwsRangeError);
expect(() => twoInts.clear(), throwsUnsupportedError);
});
group('BitMatrix', () {
test('constructor & access', () {
var matrix = BitMatrix(4, 2);
expect(matrix.length, 4);
expect(matrix[0].length, 2);
matrix[0][0] = true;
matrix[3][1] = true;
expect(matrix[1][0], false);
expect(matrix[1][1], false);
expect(matrix[0][0], true);
expect(matrix[3][1], true);
expect(() => BitMatrix(-1, 0), throwsArgumentError);
expect(() => BitMatrix(0, -1), throwsArgumentError);
expect(() => matrix[-1], throwsRangeError);
expect(() => matrix[4], throwsRangeError);
expect(() => matrix.clear(), throwsUnsupportedError);
});
test('eliminate', () {
var matrix = BitMatrix(3, 3);
matrix[0][0] = true;
matrix[1][1] = true;
matrix[2][2] = true;
expect(matrix.eliminate(), matrix.eliminate());
expect(matrix.eliminate(), [0, 1, 2]);
matrix.reset();
matrix[2][0] = true;
matrix[1][1] = true;
matrix[0][2] = true;
expect(matrix.eliminate(), matrix.eliminate());
expect(matrix.eliminate(), [0, 1, 2]);
matrix = BitMatrix(3, 4);
matrix[0].fillRange(0, 4, true);
matrix[1].fillRange(2, 4, true);
expect(matrix.eliminate(), [0, 2, -1]);
matrix.reset();
matrix[0].fillRange(0, 4, true);
matrix[1].fillRange(2, 4, true);
matrix[2].fillRange(0, 4, true);
expect(matrix.eliminate(), [0, 2, -1]);
});
});
group('generate & solve matrices', () {
test('has solutions', () {
expectSolution(
4, [9, 2, 4, 8].map((i) => BigInt.from(i)).toList(), BigInt.from(5));
expectSolution(
4, [9, 2, 4, 8].map((i) => BigInt.from(i)).toList(), BigInt.from(7));
expectSolution(
4, [9, 2, 4, 8].map((i) => BigInt.from(i)).toList(), BigInt.from(0));
});
test('has no solutions', () {
expectNoSolution(
4, [9, 2, 4].map((i) => BigInt.from(i)).toList(), BigInt.from(1));
expectNoSolution(
4, [9, 2, 4].map((i) => BigInt.from(i)).toList(), BigInt.from(3));
expectNoSolution(
4, [9, 2, 4].map((i) => BigInt.from(i)).toList(), BigInt.from(5));
expectNoSolution(
4, [9, 2, 4].map((i) => BigInt.from(i)).toList(), BigInt.from(7));
expectNoSolution(
4, [9, 2, 4].map((i) => BigInt.from(i)).toList(), BigInt.from(8));
});
});
group('CrcFlipper', () {
group('reflected', () {
var crcFuncs = <ParametricCrc>[
Crc16Kermit(), // input reflected
Crc16B(), // input reflected + init + final mask
];
crcFuncs.forEach((crc) {
test(crc.runtimeType,
() => testFlipper(crc, '1234', 16, 31, CrcValue(0xba55)));
});
});
group('regular', () {
var crcFuncs = <ParametricCrc>[
Crc16GeniBus(), // not reflected + init + final mask
Crc16Profibus(), // not reflected + init + final mask
Crc16LJ1200(), // not reflected
];
crcFuncs.forEach((crc) {
test(crc.runtimeType,
() => testFlipper(crc, '1234', 16, 31, CrcValue(0xba55)));
});
});
test('> 64 bits', () {
var inputMessage = 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA';
var positions = inputMessage.codeUnits
.asMap()
.entries
.where((e) =>
(e.value >= 0x61 && e.value < 0x61 + 26) ||
(e.value >= 0x41 && e.value < 0x41 + 26))
.map((e) => e.key * 8 + 5)
.toSet();
var crc = MultiCrc([Crc16(), Crc32C(), Crc64Xz()]);
var target = BigInt.parse('f62b51bacd1cfa11ca3812556109', radix:16);
print(CrcValue(target));
var flipper = CrcFlipper(crc);
var solution = flipper.flipWithData(
inputMessage.codeUnits, positions, CrcValue(target));
var tmp = List.of(inputMessage.codeUnits, growable: false);
solution.forEach((bitPosition) {
var mask = 1 << (bitPosition % 8);
tmp[bitPosition ~/ 8] ^= mask;
});
var outputMessage = String.fromCharCodes(tmp);
print(outputMessage);
});
});
}
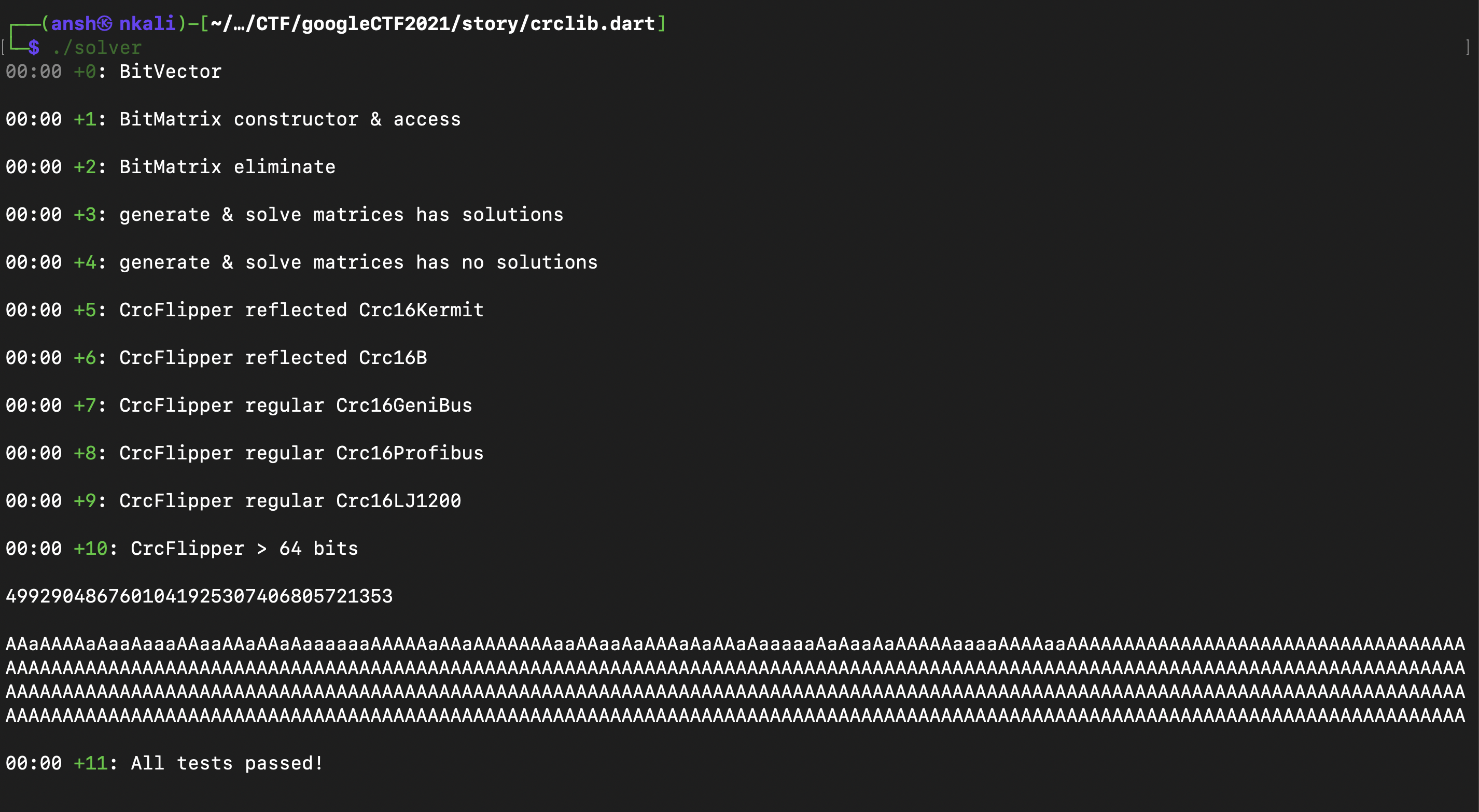
So what we inputted into the server was 512 capital ‘A’s and based on the random CRC values outputted by the server, we modified the CRC bit flipper to get the corresponding text :
We were the 13th solver for this challenge so that was pretty neat :
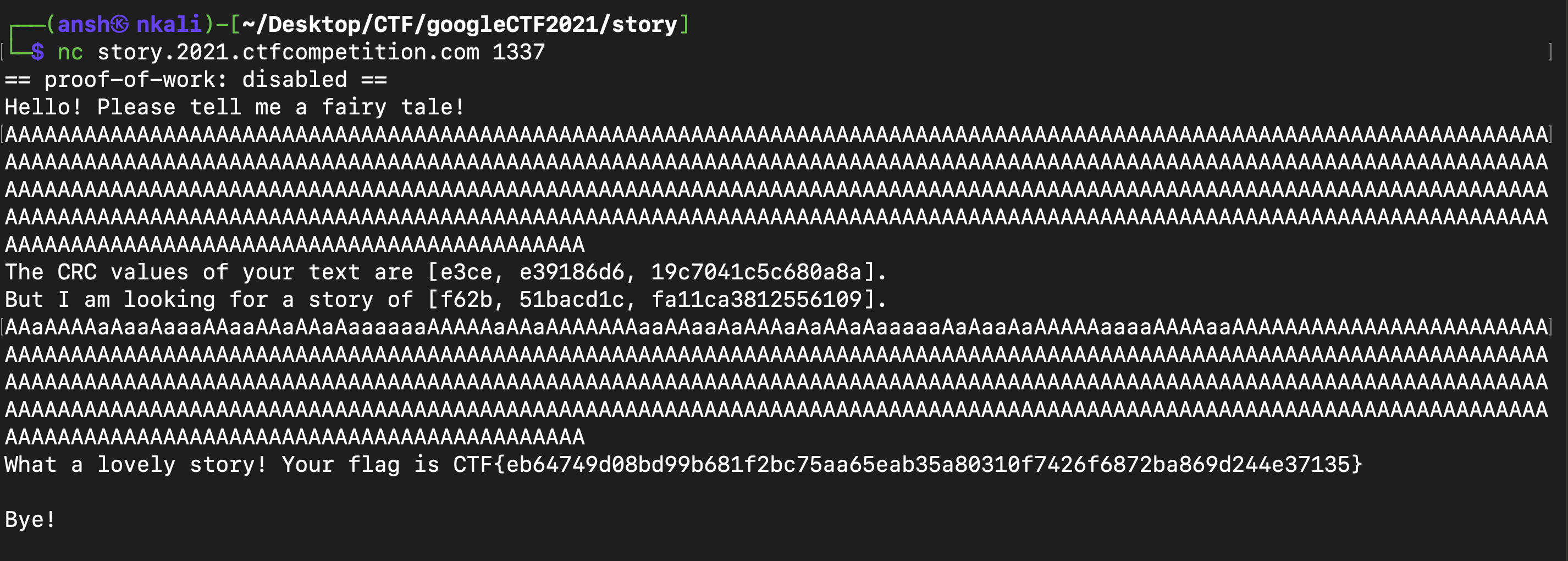
Flag : CTF{eb64749d08bd99b681f2bc75aa65eab35a80310f7426f6872ba869d244e37135}
Pythia
The server source code provided :
#!/usr/bin/python -u
import random
import string
import time
from base64 import b64encode, b64decode
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
from cryptography.hazmat.primitives.kdf.scrypt import Scrypt
max_queries = 150
query_delay = 10
passwords = [bytes(''.join(random.choice(string.ascii_lowercase) for _ in range(3)), 'UTF-8') for _ in range(3)]
flag = open("flag.txt", "rb").read()
def menu():
print("What you wanna do?")
print("1- Set key")
print("2- Read flag")
print("3- Decrypt text")
print("4- Exit")
try:
return int(input(">>> "))
except:
return -1
print("Welcome!\n")
key_used = 0
for query in range(max_queries):
option = menu()
if option == 1:
print("Which key you want to use [0-2]?")
try:
i = int(input(">>> "))
except:
i = -1
if i >= 0 and i <= 2:
key_used = i
else:
print("Please select a valid key.")
elif option == 2:
print("Password?")
passwd = bytes(input(">>> "), 'UTF-8')
print("Checking...")
# Prevent bruteforce attacks...
time.sleep(query_delay)
if passwd == (passwords[0] + passwords[1] + passwords[2]):
print("ACCESS GRANTED: " + flag.decode('UTF-8'))
else:
print("ACCESS DENIED!")
elif option == 3:
print("Send your ciphertext ")
ct = input(">>> ")
print("Decrypting...")
# Prevent bruteforce attacks...
time.sleep(query_delay)
try:
nonce, ciphertext = ct.split(",")
nonce = b64decode(nonce)
ciphertext = b64decode(ciphertext)
except:
print("ERROR: Ciphertext has invalid format. Must be of the form \"nonce,ciphertext\", where nonce and ciphertext are base64 strings.")
continue
kdf = Scrypt(salt=b'', length=16, n=2**4, r=8, p=1, backend=default_backend())
key = kdf.derive(passwords[key_used])
try:
cipher = AESGCM(key)
plaintext = cipher.decrypt(nonce, ciphertext, associated_data=None)
except:
print("ERROR: Decryption failed. Key was not correct.")
continue
print("Decryption successful")
elif option == 4:
print("Bye!")
break
else:
print("Invalid option!")
print("You have " + str(max_queries - query) + " trials left...\n")
The entire reason we played in this CTF was to solve this challenge hence the team name “gcmTime”. Lets break down the code. First a list of 3 tuples or passwords is generated. They are randomly chosen from all the lowercase alphabets a to z. For example, the passwords could be { (c, m, i), (o, f, l), (q, x, s) }. After that we are presented with four options. The first option allows us to set a key which is based on the positional index of the password list. So if we choose our key as 2, this would correspond to a key (q, x, s) in our previous example. The second option is what we have to use for getting the flag. It asks us to input a continuous string of the password (so cmioflqxs for example) and if we have successfully found that, we get the flag. Choosing the fourth option simply allows us to exit the program session.
The third option is where the most interesting stuff happens. We are prompted to send a ciphertext and nonce encoded in base 64. A relatively new kdf or password based key derivation function known as Scrypt is used to generate a key from the password / key that we specified in option 1 (to set the key i.e. password).
It works the following way and is explained in detail in this video :
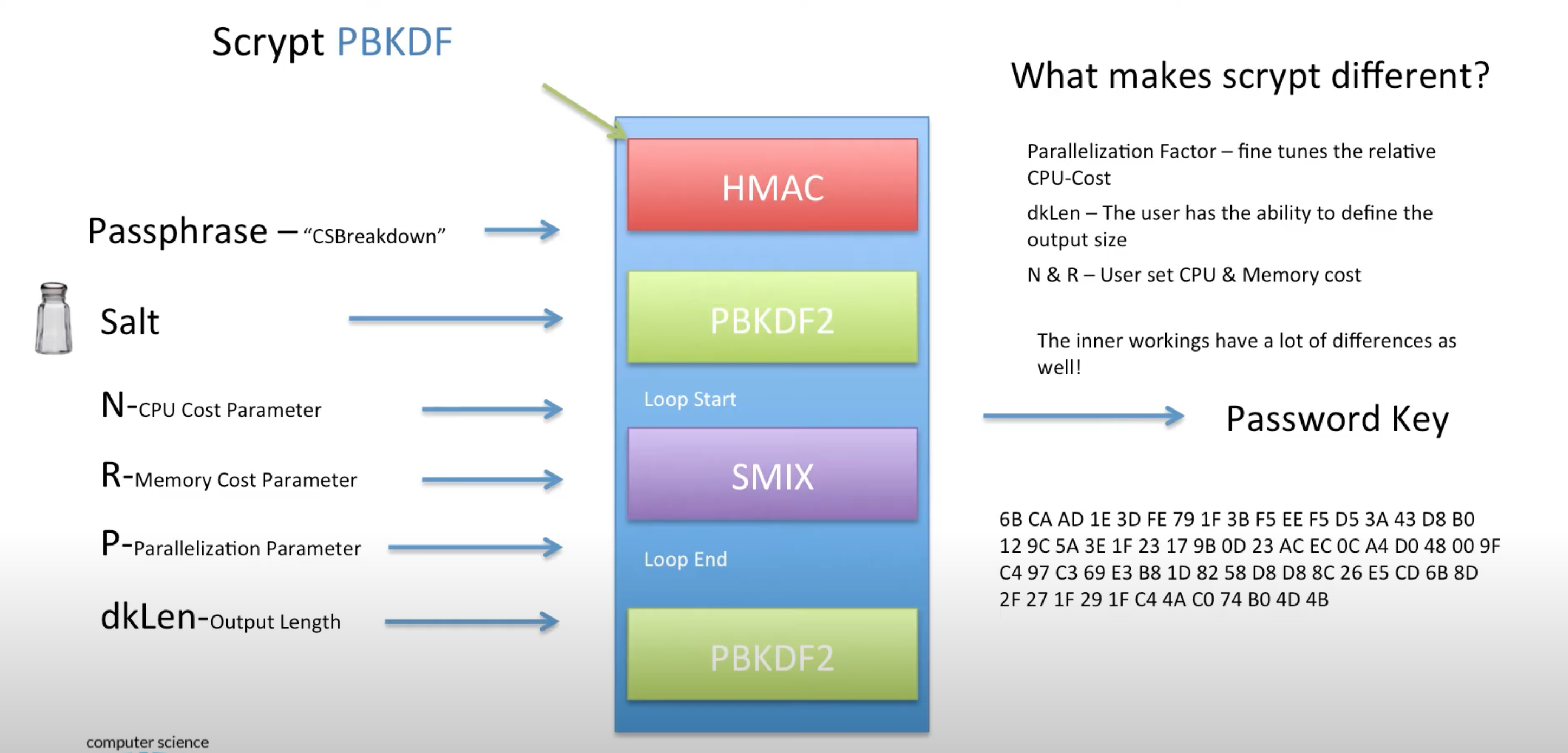
After that, an AES-GCM cipher object is generated from this key and is used to decrypt the ciphertext. If the decryption was successful (meaning that our ciphertext did correspond to the actual key/password), the server would prompt us with “Decryption successful” and otherwise it would prompt us with a failure in decryption. We have a maximum of 150 queries and each query is delayed by 10 seconds to prevent possible bruteforce attacks (by making it take too long in the server interaction since there are only 26 cubed or 17,576 password possibilities). A quick reminder into how AES-GCM (which is widely used now) works :
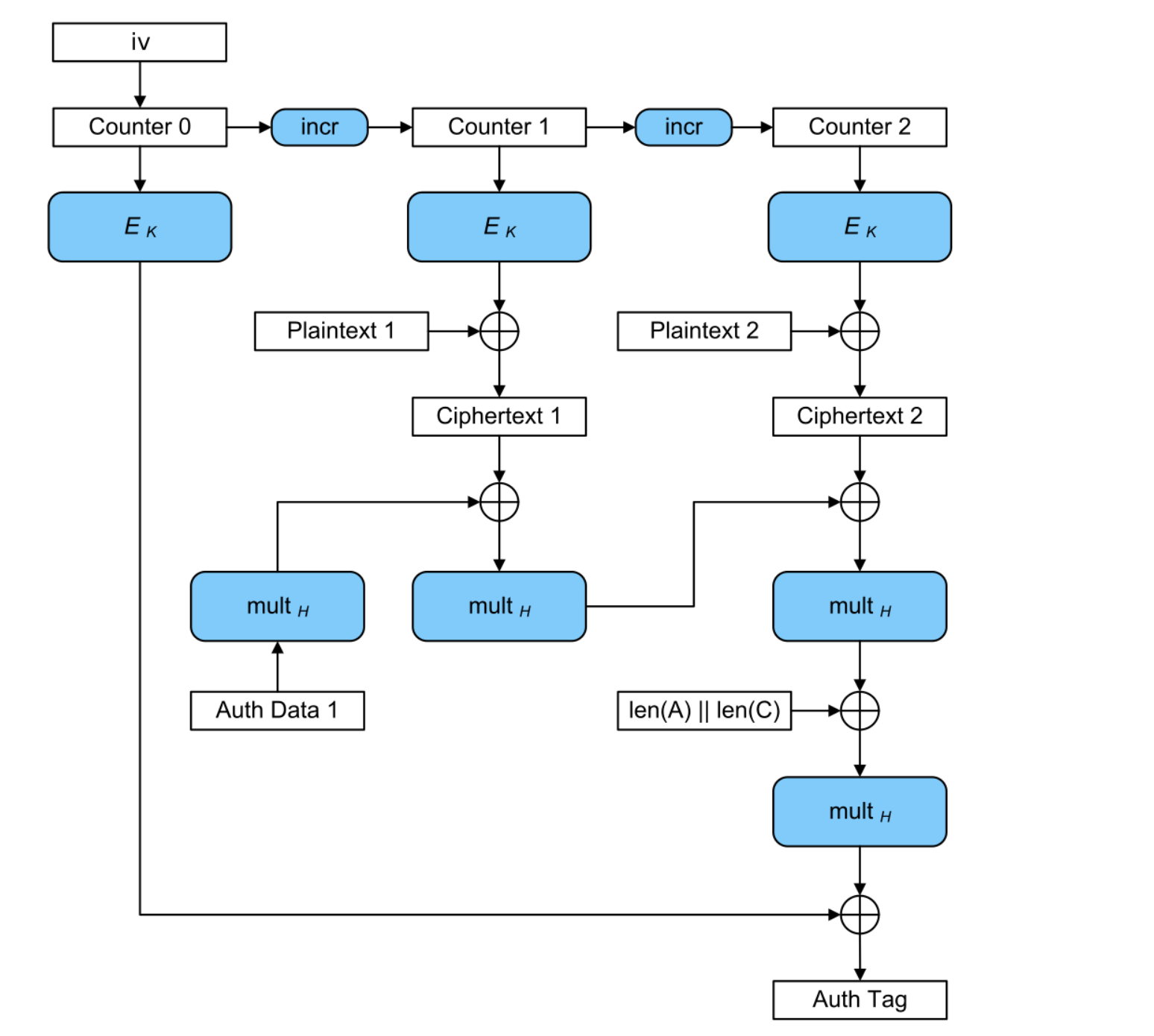
So we have an oracle! After some research, we found just what we needed. There has been some pretty new academic literature on Partitioning Oracle Attacks which was the title of this paper published by Julia Len, Paul Grubbs and Thomas Ristenpart of Cornell University in 2020. They describe partitioning oracles as a new class of decryption error oracles which, conceptually, take a ciphertext as input and output whether the decryption key belongs to some known subset of keys. The attack works by creating key multi-collisions which is when a ciphertext is created such that its decryption succeeds under k number of keys.
In our case, we could first create a partition which is a ciphertext which can decrypt under a fairly large number of keys (say 1000) and once we find the correct partition, we could use a binary search algorithm to find the correct key within that partition. This process will have to be repeated 3 times to find the triple set of 3 letter passwords. Sounds awesome! They have even written a Sage implementation of their attack for AEAD modes such as GCM over here which is exactly what we needed.
We first precomputed an exhaustive partion list of 1000 keys locally (written in Sage) in order to speed up the actual process when connecting with the server. The number 1000 was chosen as it struck a good balance between the size of the partition and time taken to generate (around 1 minute). Since there are only 17,576 possible possibilities for the key, finding the first chunk/partition would take at worst 18 queries. The script for that can be found here. The actual partition list can be found here. After that, a binary search algorithm could be employed to find the correct key and this would take at most 10 queries. We have 49 queries per password since there are 3 passwords which gives us plenty of room to spare.
Our actual Sage solve script :
from cryptography.hazmat.primitives.ciphers import (
Cipher, algorithms, modes
)
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
from cryptography.exceptions import InvalidTag
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from Crypto.Util.number import long_to_bytes, bytes_to_long
from bitstring import BitArray, Bits
import binascii
import sys
import random
import string
import time
import math
from base64 import b64encode, b64decode
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
from cryptography.hazmat.primitives.kdf.scrypt import Scrypt
from Crypto.Util.number import *
from pwn import *
from functools import lru_cache
ALL_ZEROS = b'\x00'*16
GCM_BITS_PER_BLOCK = 128
def check_correctness(keyset, nonce, ct):
flag = True
for i in range(len(keyset)):
aesgcm = AESGCM(key)
try:
aesgcm.decrypt(nonce, ct, None)
except InvalidTag:
print('key %s failed' % i)
flag = False
if flag:
print("All %s keys decrypted the ciphertext" % len(keyset))
def pad(a):
if len(a) < GCM_BITS_PER_BLOCK:
diff = GCM_BITS_PER_BLOCK - len(a)
zeros = ['0'] * diff
a = a + zeros
return a
def bytes_to_element(val, field, a):
bits = BitArray(val)
result = field.fetch_int(0)
for i in range(len(bits)):
if bits[i]:
result += a^i
return result
def multi_collide_gcm(keyset, nonce, tag, first_block=None, use_magma=False):
# initialize matrix and vector spaces
P.<x> = PolynomialRing(GF(2))
p = x^128 + x^7 + x^2 + x + 1
GFghash.<a> = GF(2^128,'x',modulus=p)
if use_magma:
t = "p:=IrreducibleLowTermGF2Polynomial(128); GFghash<a> := ext<GF(2) | p>;"
magma.eval(t)
else:
R = PolynomialRing(GFghash, 'x')
# encode length as lens
if first_block is not None:
ctbitlen = (len(keyset) + 1) * GCM_BITS_PER_BLOCK
else:
ctbitlen = len(keyset) * GCM_BITS_PER_BLOCK
adbitlen = 0
lens = (adbitlen << 64) | ctbitlen
lens_byte = int(lens).to_bytes(16,byteorder='big')
lens_bf = bytes_to_element(lens_byte, GFghash, a)
# increment nonce
nonce_plus = int((int.from_bytes(nonce,'big') << 32) | 1).to_bytes(16,'big')
# encode fixed ciphertext block and tag
if first_block is not None:
block_bf = bytes_to_element(first_block, GFghash, a)
tag_bf = bytes_to_element(tag, GFghash, a)
keyset_len = len(keyset)
if use_magma:
I = []
V = []
else:
pairs = []
for k in keyset:
# compute H
aes = AES.new(k, AES.MODE_ECB)
H = aes.encrypt(ALL_ZEROS)
h_bf = bytes_to_element(H, GFghash, a)
# compute P
P = aes.encrypt(nonce_plus)
p_bf = bytes_to_element(P, GFghash, a)
if first_block is not None:
# assign (lens * H) + P + T + (C1 * H^{k+2}) to b
b = (lens_bf * h_bf) + p_bf + tag_bf + (block_bf * h_bf^(keyset_len+2))
else:
# assign (lens * H) + P + T to b
b = (lens_bf * h_bf) + p_bf + tag_bf
# get pair (H, b*(H^-2))
y = b * h_bf^-2
if use_magma:
I.append(h_bf)
V.append(y)
else:
pairs.append((h_bf, y))
# compute Lagrange interpolation
if use_magma:
f = magma("Interpolation(%s,%s)" % (I,V)).sage()
else:
f = R.lagrange_polynomial(pairs)
coeffs = f.list()
coeffs.reverse()
# get ciphertext
if first_block is not None:
ct = list(map(str, block_bf.polynomial().list()))
ct_pad = pad(ct)
ct = Bits(bin=''.join(ct_pad))
else:
ct = ''
for i in range(len(coeffs)):
ct_i = list(map(str, coeffs[i].polynomial().list()))
ct_pad = pad(ct_i)
ct_i = Bits(bin=''.join(ct_pad))
ct += ct_i
ct = ct.bytes
return ct+tag
keyList = [a + b + c for a in string.ascii_lowercase for b in string.ascii_lowercase for c in string.ascii_lowercase]
#keyList = [a + b for a in string.ascii_lowercase for b in string.ascii_lowercase]
scryptedKeyList = []
for key in keyList:
kdf = Scrypt(salt=b'', length=16 , n=2 **4 , r=8 , p=1 , backend=default_backend())
key = kdf.derive(key.encode())
scryptedKeyList.append(key)
local = False
debug = False
if local:
r = process(["python3", "server.py"], level='debug') if debug else process(["python3", "server.py"])
else:
r = remote("pythia.2021.ctfcompetition.com", 1337 , level = 'debug') if debug else remote("pythia.2021.ctfcompetition.com", 1337 )
collisionLength = 1000
chunks = [scryptedKeyList[x:x+collisionLength] for x in range(0 , len(scryptedKeyList), collisionLength)]
cipherList = [b'.....', b'....', b'.....', .....]
#The full cipherList (removed from writeup since it is too long) can be found in the link below :
#https://github.com/Angmar2722/Angmar2722.github.io/blob/master/assets/ctfFiles/2021/google2021/Pythia/cipherList.txt
def getPassword(key_used):
option = b"1"
r.sendlineafter(">>> ", option)
r.sendlineafter(">>> ", key_used)
first_block = b'\x01'
nonce = b'\x01'*12
tag = b'\x00'*16
index = -1
output = b""
while (output != b"Decryption successful\n"):
index += 1
option = b"3"
r.sendlineafter(">>> ", option)
payloadCT = cipherList[index]
r.sendlineafter(">>> ", b64encode(nonce) + b"," + b64encode(payloadCT) )
r.recvline()
output = r.recvline()
print(output)
guess = chunks[index]
for _ in range(math.ceil(math.log(collisionLength, 2 ))):
option = b"3"
r.sendlineafter(">>> ", option)
keyset = guess[:len(guess)//2 ]
payloadCT = multi_collide_gcm(keyset, nonce, tag, first_block=first_block)
r.sendlineafter(">>> ", b64encode(nonce) + b"," + b64encode(payloadCT) )
r.recvline()
output = r.recvline()
if (output != b"Decryption successful\n"):
guess = guess[len(guess)//2 :]
else:
guess = keyset
return keyList[scryptedKeyList.index(guess[0]) ]
passwordList = []
passwordList.append( getPassword(b'0') )
passwordList.append( getPassword(b'1') )
passwordList.append( getPassword(b'2') )
print(passwordList)
option = b"2"
r.sendlineafter(">>> ", option)
r.sendlineafter(">>> ", ''.join(passwordList))
print(r.recvline())
print(r.recvline())
exit(0 )
All in all, it took around 11 minutes to run (considerable time was saved due to the precomputed cipher list) :
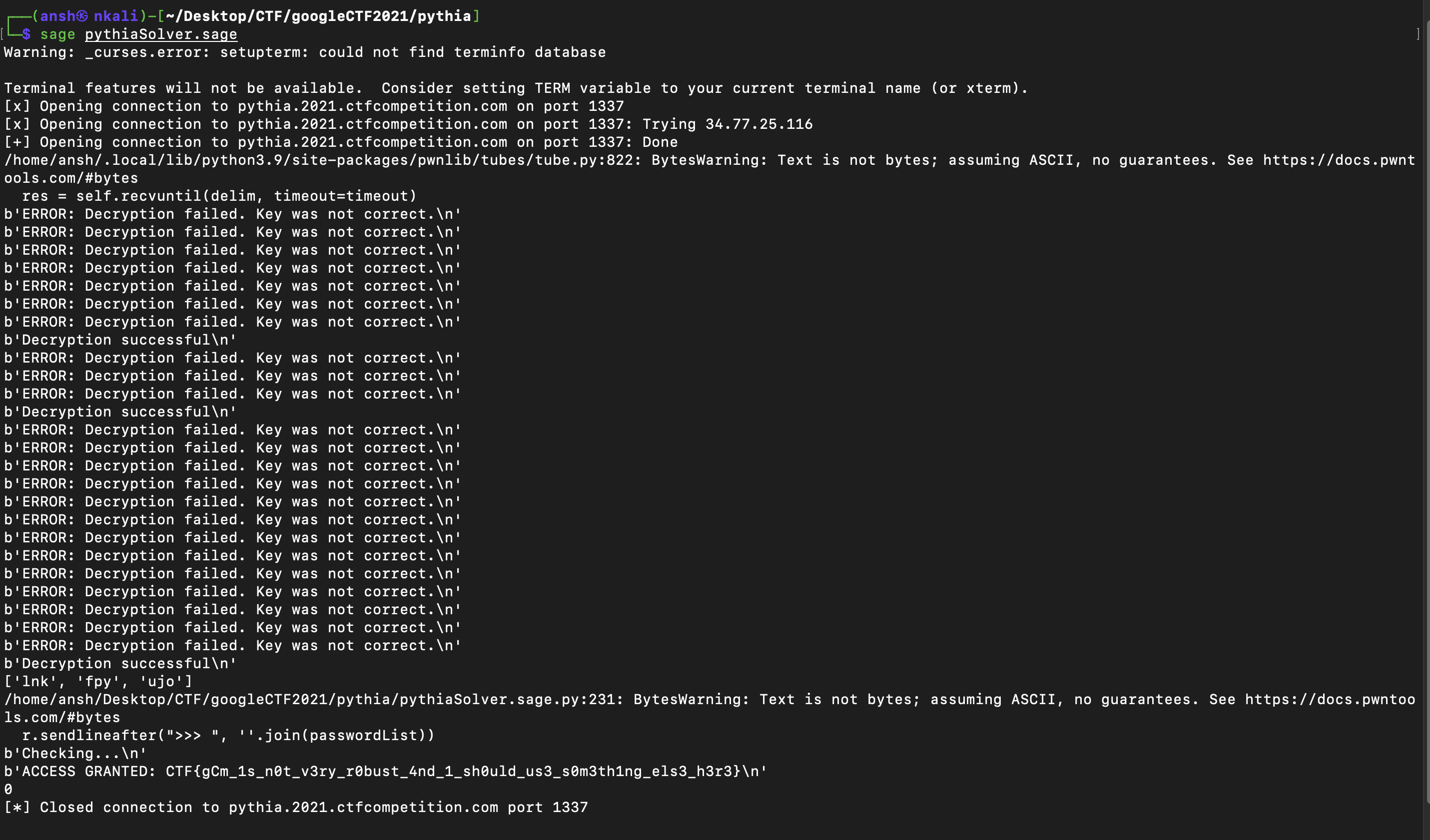
We were the 9th solver for this challenge so that was pretty cool, especially the fact that our team name was in the company of some legendary CTF teams like PPP, Dice Gang and pasten). We also did our team name ‘gcmTime’ justice. Even though this had more than twice as many solves as Story, this was still a harder cryptography challenge.
Flag : CTF{gCm_1s_n0t_v3ry_r0bust_4nd_1_sh0uld_us3_s0m3th1ng_els3_h3r3}
Filestore
The server source code provided :
# Copyright 2021 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os, secrets, string, time
from flag import flag
def main():
# It's a tiny server...
blob = bytearray(2**16)
files = {}
used = 0
# Use deduplication to save space.
def store(data):
nonlocal used
MINIMUM_BLOCK = 16
MAXIMUM_BLOCK = 1024
part_list = []
while data:
prefix = data[:MINIMUM_BLOCK]
ind = -1
bestlen, bestind = 0, -1
while True:
ind = blob.find(prefix, ind+1)
if ind == -1: break
length = len(os.path.commonprefix([data, bytes(blob[ind:ind+MAXIMUM_BLOCK])]))
if length > bestlen:
bestlen, bestind = length, ind
if bestind != -1:
part, data = data[:bestlen], data[bestlen:]
part_list.append((bestind, bestlen))
else:
part, data = data[:MINIMUM_BLOCK], data[MINIMUM_BLOCK:]
blob[used:used+len(part)] = part
part_list.append((used, len(part)))
used += len(part)
assert used <= len(blob)
fid = "".join(secrets.choice(string.ascii_letters+string.digits) for i in range(16))
files[fid] = part_list
return fid
def load(fid):
data = []
for ind, length in files[fid]:
data.append(blob[ind:ind+length])
return b"".join(data)
print("Welcome to our file storage solution.")
# Store the flag as one of the files.
store(bytes(flag, "utf-8"))
while True:
print()
print("Menu:")
print("- load")
print("- store")
print("- status")
print("- exit")
choice = input().strip().lower()
if choice == "load":
print("Send me the file id...")
fid = input().strip()
data = load(fid)
print(data.decode())
elif choice == "store":
print("Send me a line of data...")
data = input().strip()
fid = store(bytes(data, "utf-8"))
print("Stored! Here's your file id:")
print(fid)
elif choice == "status":
print("User: ctfplayer")
print("Time: %s" % time.asctime())
kb = used / 1024.0
kb_all = len(blob) / 1024.0
print("Quota: %0.3fkB/%0.3fkB" % (kb, kb_all))
print("Files: %d" % len(files))
elif choice == "exit":
break
else:
print("Nope.")
break
try:
main()
except Exception:
print("Nope.")
time.sleep(1)
This challenge involved understanding the storage mechanism shown here. The first choice ‘load’ would print the contents of a file given the file ID. The second option stores the provided data. The server stores it in a rather peculiar way by using data deduplication. For example, if the existing storage comprised of “flag, hello there, …..” and if you added the word “hello”, it would still look like “flag, hello there, …..” as the word ‘hello’ is repeated in the original data structure. This process of removing duplicates saves a lot of space but has some vulnerabilities. The index or position of the stored string is tracked by the
files dictionary. The third option ‘status’ prints the amount of memory currently occupied (if there is a duplication, there is no change).
Suppose currently the strings stored were “CTF{this_is_a_test_flag}”. If I made a loop which added all printable ASCII characters after “CTF{“ and then checked for the status or memory occupied, the string which causes no change in memory (i.e. “CTF{t”) would be a character of the flag. This is how we solved it, by checking which character caused no change in memory size and hence slowly leaking the flag, character by character.
The solve script :
from pwn import *
local = False
debug = False
if local:
r = process(["python3", "filestore/filestore.py"], level='debug') if debug else process(["python3", "filestore/filestore.py"])
else:
r = remote("filestore.2021.ctfcompetition.com", 1337, level = 'debug') if debug else remote("filestore.2021.ctfcompetition.com", 1337)
possible_chars = [chr(i) for i in range(33, 127)]
FLAG = "CTF{"
r.recvuntil(b"- exit\n")
for _ in range(30):
try:
for char in possible_chars:
r.sendline(b"status")
r.recvuntil(b"Quota: ")
current_quota = r.recvline(keepends=False)
r.sendline(b"store")
r.sendline(FLAG[-15:] + char)
r.sendline(b"status")
r.recvuntil(b"Quota: ")
new_quota = r.recvline(keepends=False)
if new_quota == current_quota:
FLAG += char
print(FLAG)
break
except EOFError:
if local:
r = process(["python3", "filestore.py"], level='debug') if debug else process(["python3", "filestore.py"])
else:
r = remote("filestore.2021.ctfcompetition.com", 1337, level = 'debug') if debug else remote("filestore.2021.ctfcompetition.com", 1337)
After running the script, we got the flag (this was the most solved challenge in the entire CTF by a considerable margin) :
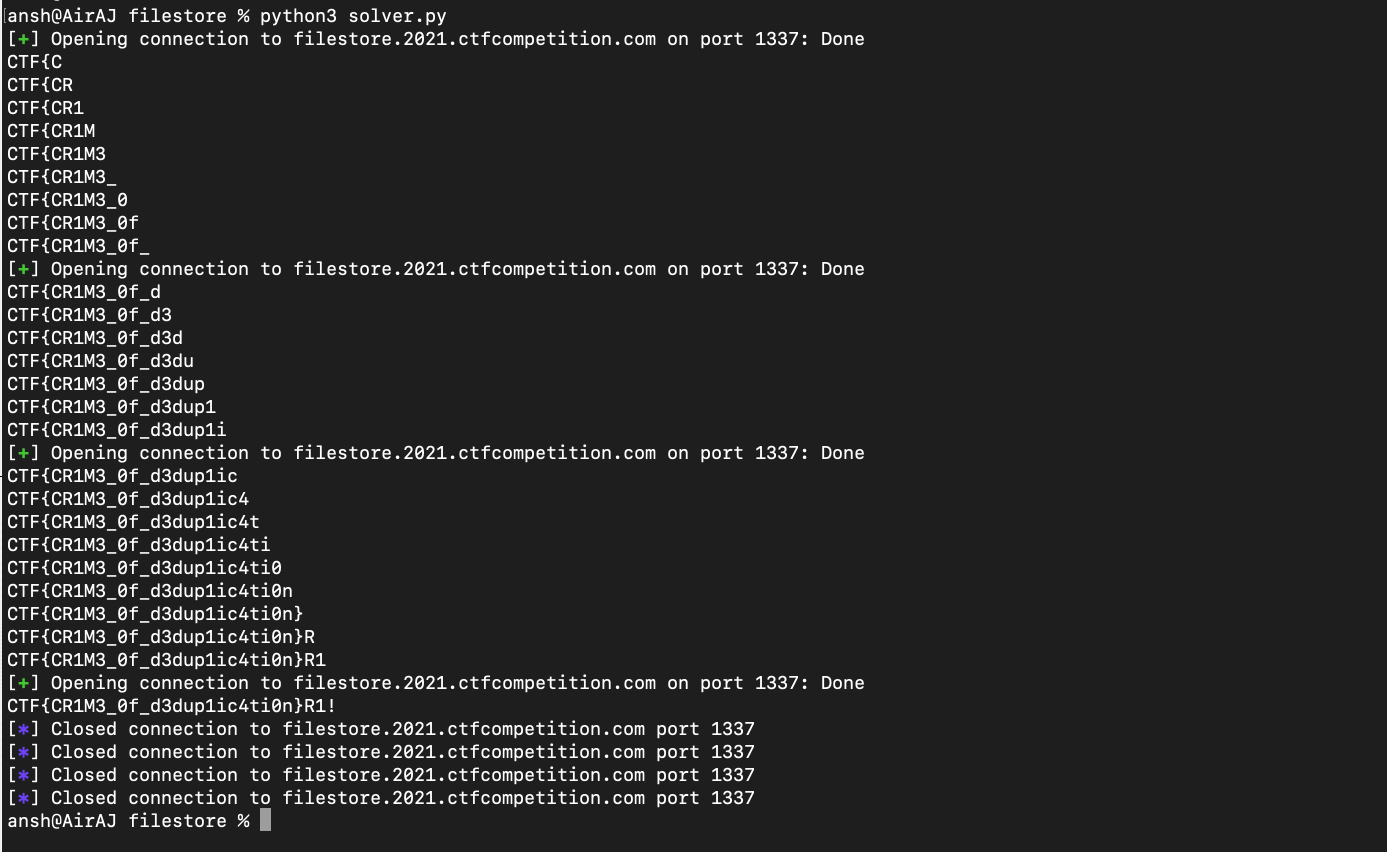
Flag : CTF{CR1M3_0f_d3dup1ic4ti0n}